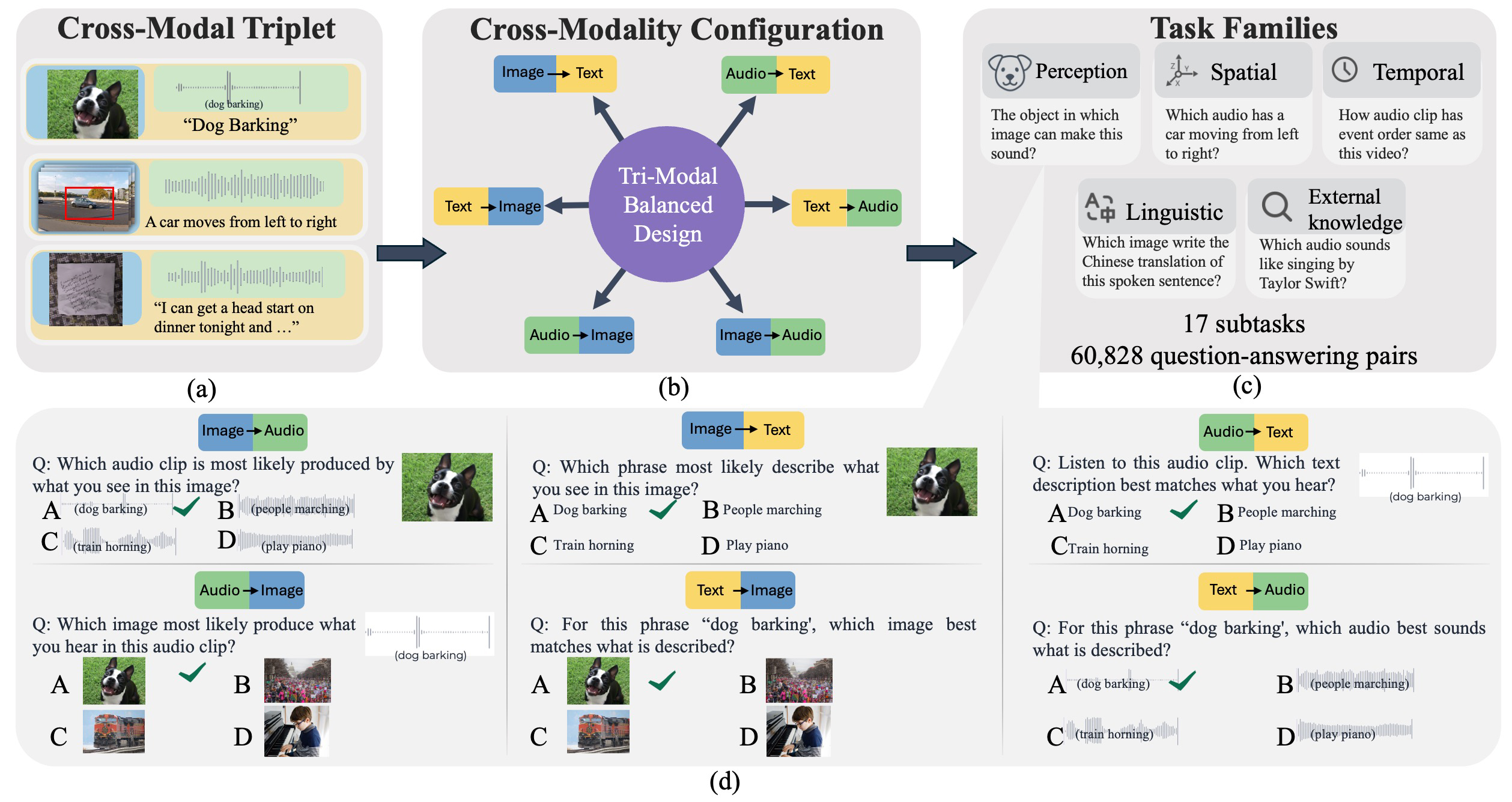
We evaluated 13 state-of-the-art omni-modal models including Gemini 2.5 Pro, Qwen2.5-Omni, EchoInk-R1, and others. The results reveal systematic weaknesses across three dimensions:
1. Task Competence Gaps
Models show strong performance on perception and linguistic tasks (best model achieves ~75%), but struggle significantly with spatial and temporal reasoning:
- Gemini 2.5 Pro: 75.9% (Perception), 76.8% (Linguistic), but only 50.1% (Spatial) and 60.8% (Temporal)
- Spatial & Temporal Reasoning: All models drop 15-25 points compared to perception tasks
- Open-source Models: Show even larger gaps, with some scoring below 40% on spatial/temporal tasks
Task Competence (by family)
2. Modality Disparity
Performance varies dramatically across modalities, with audio being the most challenging:
- Audio vs. Text: Models drop 20-49 points when audio replaces text inputs
- Audio vs. Vision: 33-point average gap, showing difficulty in aligning heterogeneous signals
- Vision vs. Text: Smaller but still significant ~15-point disparity
- Consistency (Std. Dev.): Best models show 10-12 point standard deviation across configurations
Modality Disparity (bars drop = worse on audio)
3. Directional Imbalance
Models exhibit asymmetric performance when context and candidate modalities are swapped:
- Vision↔Text: 9-17 point gaps between V→T and T→V directions
- Audio↔Text: 6-8 point asymmetries in bidirectional settings
- Audio↔Vision: Nearly symmetric but with much lower overall accuracy
- Root Cause: Training data imbalance—models heavily trained on image-to-text QA, less on inverse directions
Human Performance
Human evaluation on sampled questions shows consistently high performance across all modalities:
- Overall Average: 91.5% accuracy (vs. 70.6% for best model)
- Perception: 91.0% (vs. 75.9%)
- Spatial: 89.7% (vs. 50.1%)
- Temporal: 88.9% (vs. 60.8%)
- Linguistic: 93.9% (vs. 76.8%)
- Knowledge: 93.9% (vs. 89.3%)
This demonstrates substantial room for improvement, especially in spatial and temporal reasoning where the human-model gap exceeds 25-30 points.